Author- Ashfaq Pathan (Data Engineer)
Move and Extract data in batches using Azure Data Factory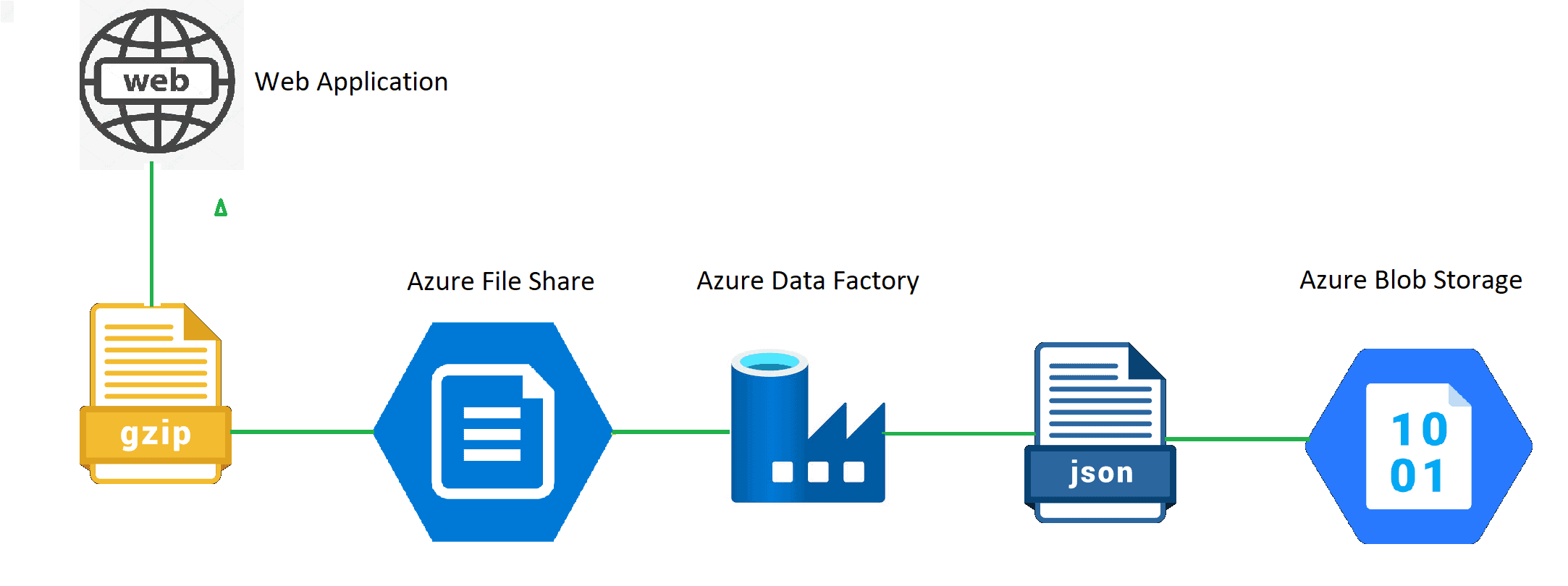
Prerequisite:
- Azure Subscription
- Azure Data Factory
- Azure Storage Account
Problem Statement:
While we were moving all the data in the last 15 min from Azure File Share to Azure Blob Storage, the volume of the data would vary in every pipeline run. Eg: In some pipeline runs last 15 min of data would be around 11GB of data movement, while in some pipeline runs it would be less than 1GB of data movement. However, pipeline execution time was similar in both cases inspite of the data volume difference resulting in inconsistent copy time.
To move the data with good speed and data size and in the expected duration, we needed a better approach.
Solution:
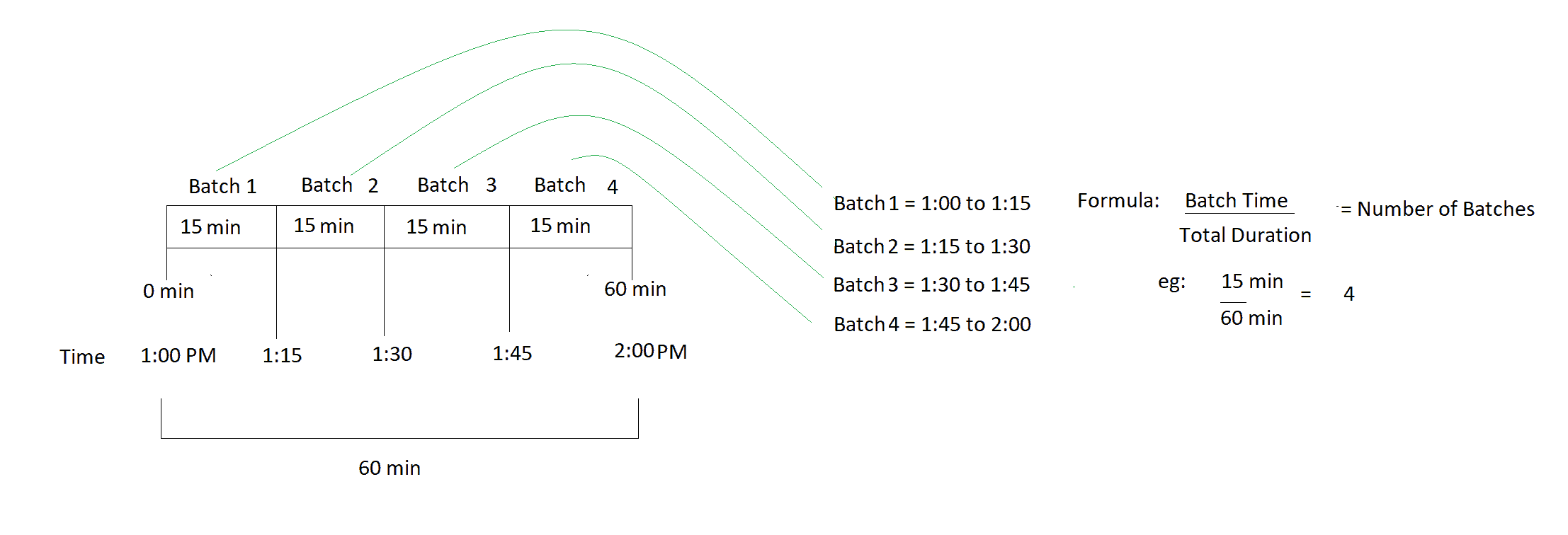
We divided the pipeline into small batches of time for example data move for the last 1hr which is 60 min can be divided into 4 groups of 15 min each then these 4 batches will run at the same time to achieve the speed once we get this the pipeline will end in expected duration.
When we divided the overall load into time batches the compute load on the pipeline was also divided among 4 batches. Hance faster execution of the pipeline.
Azure Storage Account
Storage Account Name: “enprodeventhubtest”: In the azure storage account, we need to have some Folders before starting with the Data factory some folders in files Share, and some containers in the Blob Storage account as follows –
Azure Blob Storage: Containers: [heartbeat]

Azure File Share: File Share: [heartbeatlogs]

Folders: [heartbeat ] Storage Account: Containers /Folder Structure.

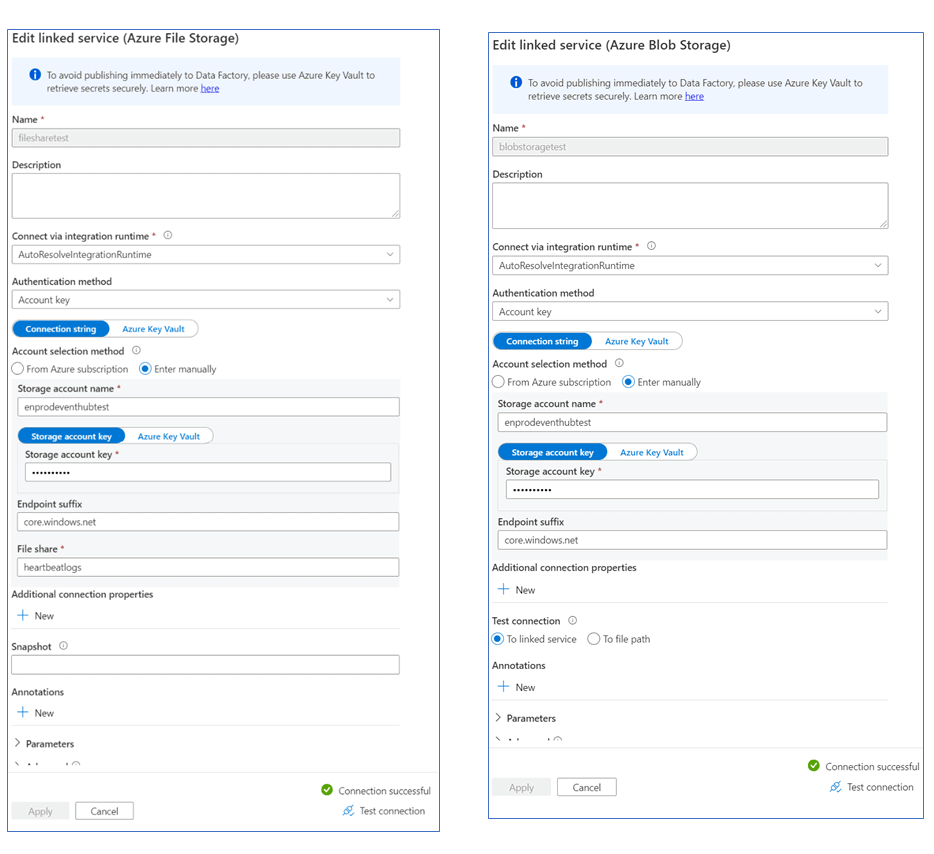
Linked Services
Linked services are much like connection strings, which define the connection information needed for the service to connect to external resources.
We must create 2 Linked Services for our AZURE DATA FACTORY pipeline to work.

Below is the screenshot of the Link service in AZURE DATA FACTORY
Azure file Share: filesharetest Azure Blob Storage: blobstoragetest
Datasets
Details

Pipeline: DataMove_BatchTime
Overview of Pipeline:
DataMove_BatchTime: In this pipeline, we have 2 parameters 4 variables 9 activities, and 1 trigger.
This pipeline will run every 1 hour every day with the help of Trigger.
Pipeline Structure
Link service:
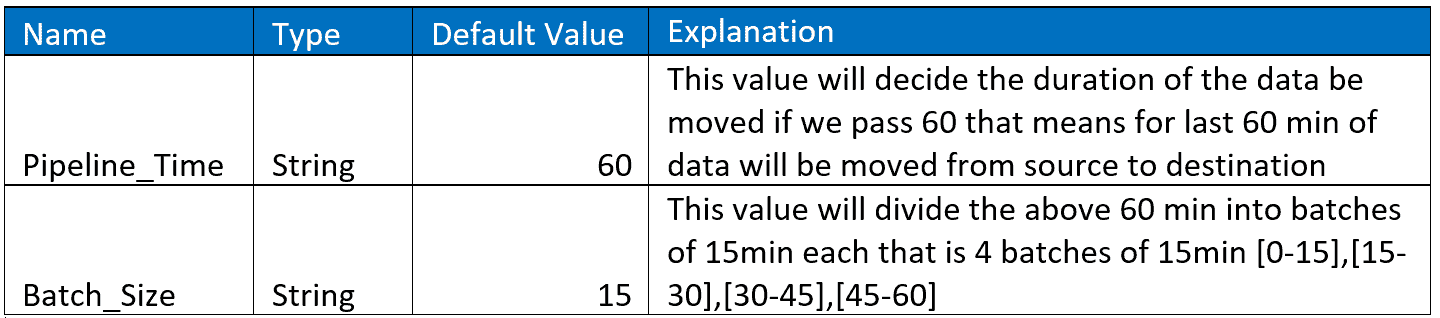
 Parameters:
Parameters:
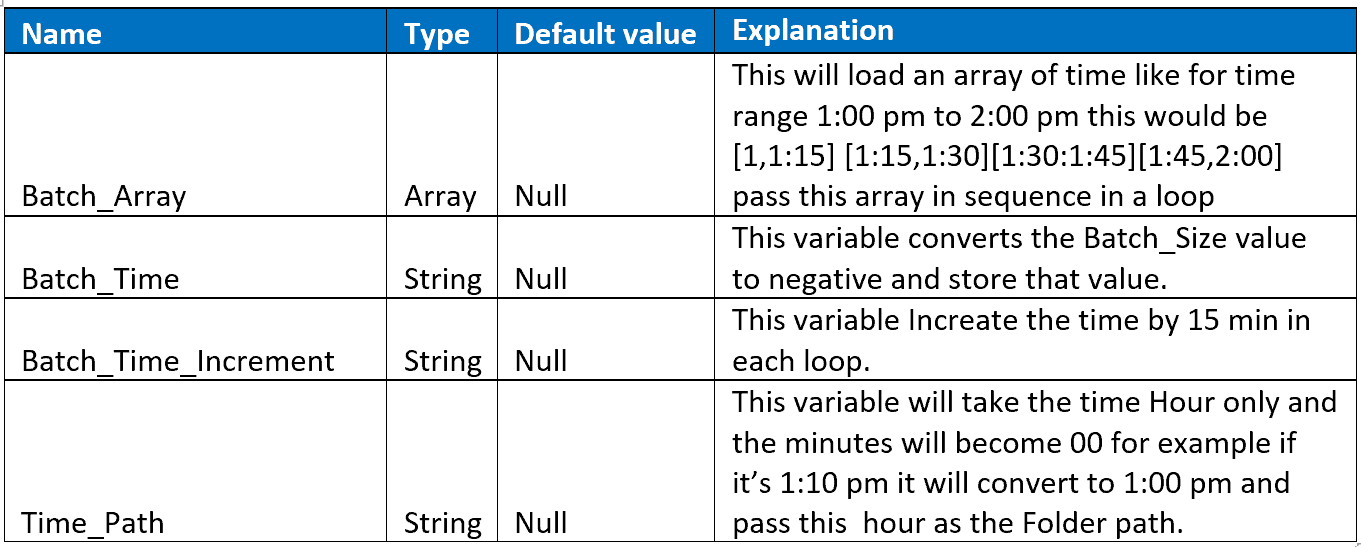
Variable:
Activity:
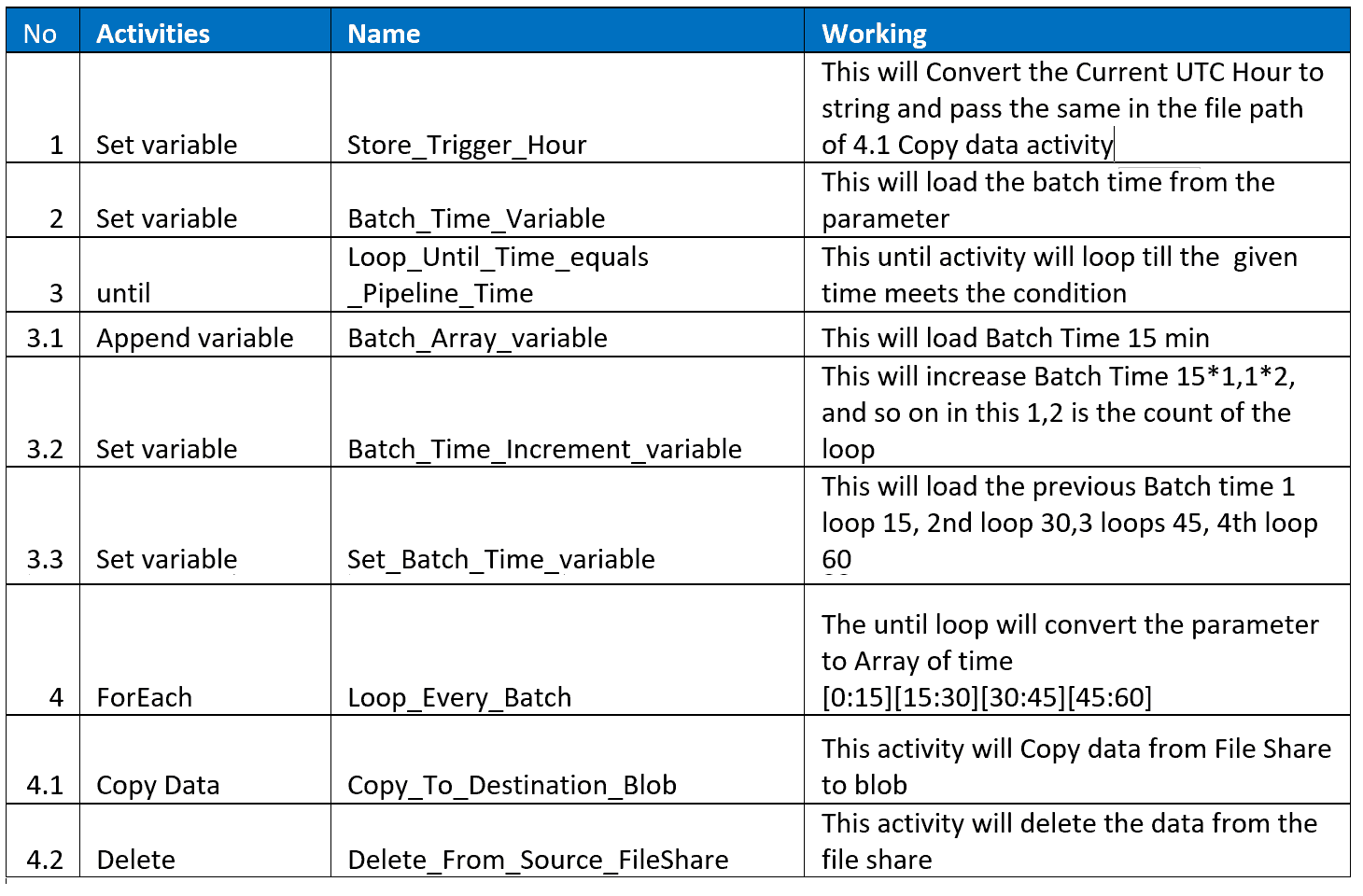
Pipeline Screenshot:
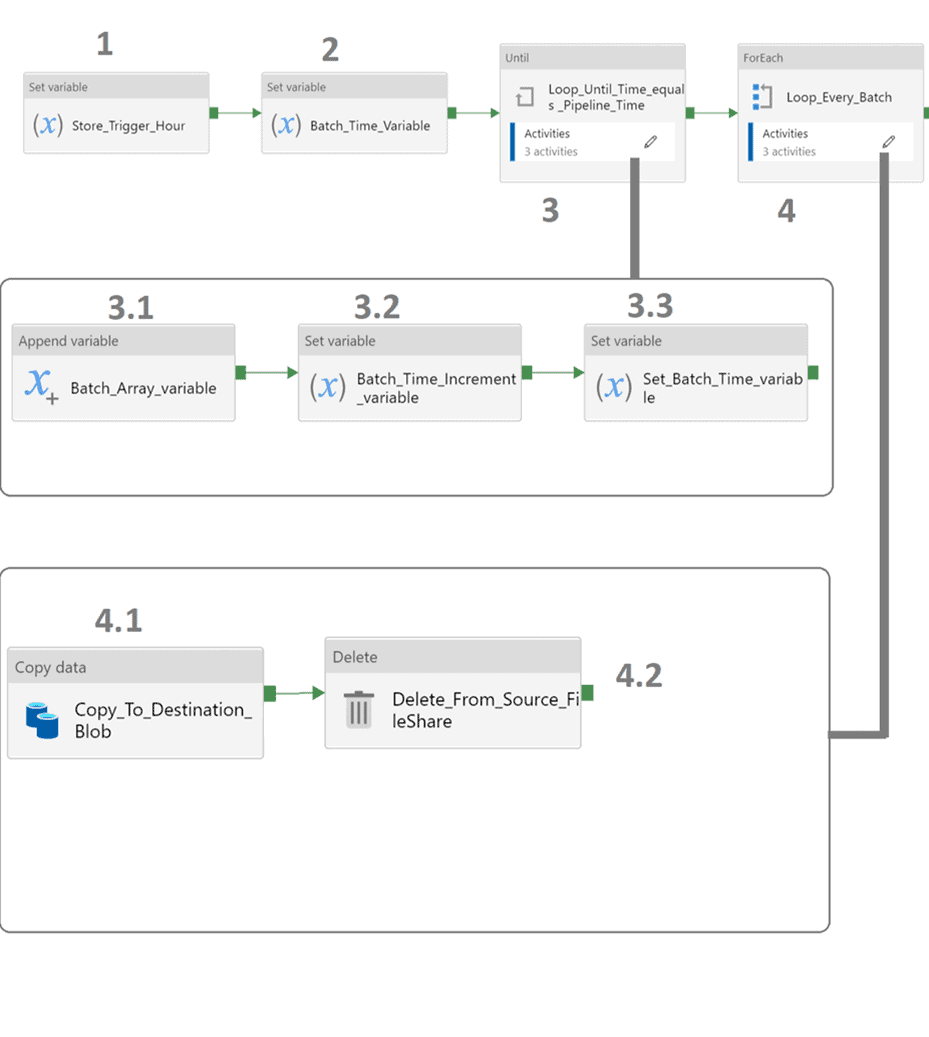
Activity, Dependency
| No | Activities | Name | Configs | Sub-Configs | Syntax |
| 1 | Set variable | Store_Trigger_Hour | |||
| Variables: | Name: | Time_Path | |||
| value: | @concat(formatDateTime(pipeline().
TriggerTime,’HH’),’:00′) |
||||
| 2 | Set variable | Batch_Time_Variable | Variables: | Name: | Batch_Time |
| value: | @string(mul(int(pipeline().parameters.
Batch_Size),-1)) |
||||
| 3 | until | Loop_Until_Time_equals _Pipeline_Time | Settings: | Expression: | @less(int(pipeline().parameters.
Pipeline_Time),mul(int(variables( ‘Batch_Time’)),-1)) |
| 3.1 | Append variable | Batch_Array_variable | Variables: | Name: | Batch_Array |
| value: | @variables(‘Batch_Time’) | ||||
| 3.2 | Set variable | Batch_Time_Increment_variable | Variables: | Name: | Batch_Time_Increment |
| value: | @string(sub(int(variables(‘Batch_Time’)),
int(pipeline().parameters.Batch_Size))) |
||||
| 3.3 | Set variable | Set_Batch_Time_variable | Variables: | Name: | Batch_Time |
| value: | @variables(‘Batch_Time_Increment’) | ||||
| 4 | ForEach | Loop_Every_Batch | Settings: | Items: | @variables(‘Batch_Array’) |
| 4.1 | Copy Data | Copy_To_Destination_Blob | General: | Retry: | 3 |
| Source: | Source Dataset: | 01_heartbeat_FS_json_source | |||
| File Path Type: | Wildcard file path | ||||
| Wildcard Path: | heartbeatlogs/@concat(‘heartbeat/’,
formatDateTime(subtractFromTime( pipeline().TriggerTime,1,’Hour’), ‘yyyy/M/dd/HH’))/*.gz |
||||
| Filter by last Modified: | |||||
| Start Time UTC :@addminutes(variables(
‘Time_Path’),int(item())) |
|||||
| End Time UTC :@addminutes(variables(
‘Time_Path’),add(int(pipeline().parameters. Batch_Size),int(item()))) |
|||||
| Recursively | YES | ||||
| Sink: | Sink Dataset: | 01_heartbeat_blob_json_sink | |||
| Copy behaviour | Preserve hierarchy | ||||
| Settings: | Data integration unit | 32 | |||
| degree of copy parallelism | 48 | ||||
| 4.2 | Delete | Delete_From_Source_FileShare | Source: | Source Dataset : | 01_heartbeat_FS_json_delete_source :Open:Connection:File path:heartbeatlogs/@concat(‘heartbeat/’,
formatDateTime(subtractFromTime( pipeline().TriggerTime,1,’Hour’), ‘yyyy/M/dd/HH’))/Null |
| File Path Type: | Wildcard file path | ||||
| Wildcard File name: | *.gz | ||||
| Filter by last Modified: | |||||
| Start Time UTC :@addminutes(variables(
‘Time_Path’),int(item())) |
|||||
| End Time UTC :@addminutes(variables(‘Time_Path’)
,add(int(pipeline().parameters.Batch_Size), int(item()))) |
|||||
| Recursively | YES |
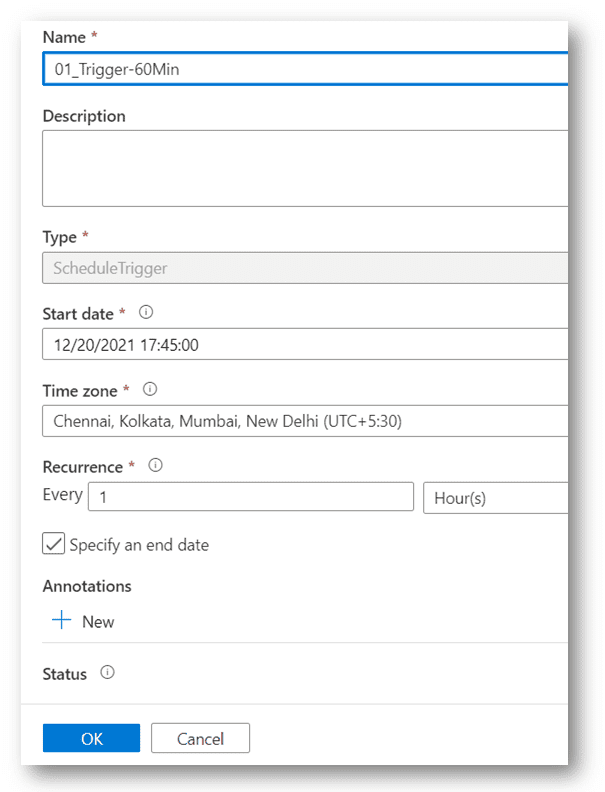
Schedule Trigger:
So as per our use case, we will set a Schedule trigger that will run the pipeline every one hour.
1. Open pipeline Add trigger.
2 Click on + NEW.
3. Configs same as below image. And click on OK